Segfaults: GDB Scripts to the Rescue
November 10, 2020
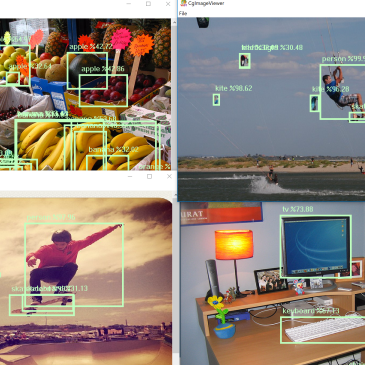
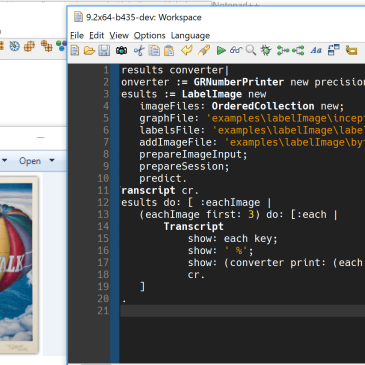
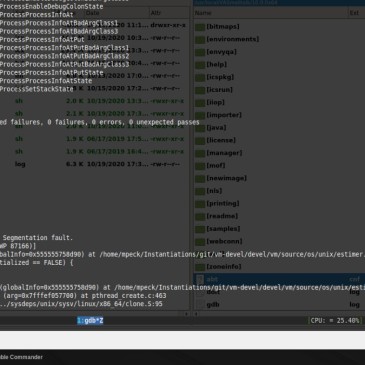
We recently discovered that we would very sporadically get a segmentation fault when running the whole test suite of the VAST Platform (VA Smalltalk) on Linux. During our initial investigation, we realized this was not something new, but that the problem had existed for many years. It happens only on Linux (not Windows), and with … More Segfaults: GDB Scripts to the Rescue